新手入门 (Getting Started)
为什么使用GdiSDK?
在地学和环境相关领域,要把专业知识「变成一个可用的软件」,一直有两个老大难问题:
专业鸿沟问题
传统的专业应用开发,往往要求一个人同时懂两件事:
领域专业知识:地质、环境、岩土工程等
计算机技术:编程语言、软件开发、系统架构等
现实中,这样的「全栈高手」非常少见,所以就会出现:
计算机专业人员不懂业务细节,很难做出真正好用的专业工具
地学和环境工程师没有充足的软件开发能力,很难把想法变成可运行的程序
项目开发周期长、沟通成本高、后期维护也很痛苦
GdiSDK 的目标,就是让 熟悉业务的工程师可以自己“搭应用”,而不必先成为专业程序员。
数据质量挑战
在实际项目中,数据处理本身也常常遇到这些问题:
数据格式不统一:不同软件、不同单位的数据格式各不相同,导来导去很费劲
处理流程复杂:步骤多、容易出错,很多都是重复劳动
质量控制困难:缺少系统化的检查机制,数据质量难以保证
这些问题叠加在一起,让数据处理既费时又费心。
下面我们看看 GdiSDK 是如何通过技术手段来解决这些问题的。
GdiSDK的技术优势
GdiSDK 通过一套完整的技术方案,来应对上面的这些现实问题:
- 标准化数据格式
基于 GDIM平台 ,提供统一的数据结构和接口,让不同来源的数据「说同一种语言」。
- 自动化处理流程
使用工作流 (pipeline) 模式,把一系列处理步骤连起来,一次配置,多次复用,尽量减少「手工点来点去」。
- 内置质量控制
通过端口类型和数据结构约束,在数据流转的各个环节做检查,尽可能在「出问题的当下」就发现问题。
- 模块化设计
把常用的数据读写、转换、分析等能力做成一个个模块,需要什么就拼什么。
- 易于扩展
除了内置模块外,也支持自定义模块开发,方便把你自己的算法和业务规则接入进来。
Hint
若您没有任何 Python 编程基础,可以参考该 Python 入门教程 来快速上手。
安装和环境搭建
Note
您也可以查看 GdiSDK 开发环境搭建视频教程 来快速了解如何搭建GdiSDK开发环境。
系统要求
在开始使用GdiSDK之前,请确保你的系统满足以下要求:
- 操作系统
Windows 10/11 (推荐)
Linux (Ubuntu 18.04+, CentOS 7+)
macOS 10.15+
- Python版本
Python 3.11
- 内存和存储
最少 4GB RAM (推荐 8GB+)
至少 2GB 可用磁盘空间
安装Python环境
如果你尚未安装Python,建议使用Miniconda或Anaconda:
Miniconda下载 (轻量版,推荐)
Anaconda下载 (支持图形界面管理)
创建虚拟环境
为了避免包冲突,强烈建议为GdiSDK创建专用的虚拟环境:
# 使用conda创建环境
conda create -n gdi-env python=3.11
conda activate gdi-env
# 或使用venv创建环境
python -m venv gdi-env
# Windows
gdi-env\Scripts\activate
# macOS/Linux
source gdi-env/bin/activate
安装GdiSDK
GdiSDK提供以下安装方式:
从压缩包安装
下载 GdiSDK压缩包 ,并解压到你的项目目录下。
注意解压后的文件夹必须命名为 gdisdk ,否则会导致无法正常导入模块。
从git安装
若你使用git,也可以直接使用 git clone 命令克隆仓库。
# 在你的项目目录下克隆仓库
git clone https://gitee.com/jimmy_kl/gdisdk.git
cd gdisdk
安装依赖
无论你使用哪种安装方式,安装完成后,都需要安装GdiSDK运行依赖。依赖安装方式如下:
# 安装依赖
pip install -r requirements.txt
Note
注意一定要在刚才创建的虚拟环境中安装依赖,否则依赖并未正确安装到到运行GdiSDK的虚拟环境中。
安装完成后,你的项目目录结构应如下:
.
├── gdisdk/ # GdiSDK代码
├── main.py # 你的项目主文件
└── ... # 你的项目其他文件
验证安装
安装完成后,验证GdiSDK是否正确安装。在你的项目文件夹根目录下创建测试脚本,并运行以下代码:
# 测试基本导入
import gdisdk
print(f"GdiSDK version: {gdisdk.__version__}")
print("GdiSDK安装成功!")
激活GdiSDK授权
GdiSDK为部分开源的Python开发包,非开源部分需要南京库仑授权激活(完全免费)。请采用以下流程激活你的GdiSDK开发包:
激活成功后,验证GdiSDK是否正确激活。
# 测试核心模块导入
from gdisdk.pipeline import PipeLine
print("GdiSDK激活成功!")
配置开发环境
为了获得最佳的开发体验,建议配置IDE:
Visual Studio Code
// .vscode/settings.json
{
"python.defaultInterpreterPath": "./gdisdk-env/bin/python",
"python.linting.enabled": true,
"python.linting.pylintEnabled": true,
"python.formatting.provider": "black"
}
PyCharm
打开项目设置 (File → Settings)
选择 Project → Python Interpreter
选择已创建的gdisdk-env环境
启用类型检查和代码格式化
注册GDIM账户
若你需要开发GDIM应用,但没有GDIM账户,则需要在GDIM注册账户。注册流程如下:
Note
若你希望在GDIM上运行你开发的应用,申请注册邀请码时「开通开发者后台」一定要选择「是」。
入门案例
让我们通过几个简单的案例快速上手GdiSDK。
案例一:提取钻孔一览表数据
假设你有一组地层数据,包含以下列:
bore_number (勘探点编号)
bore_top (孔顶高程)
layer_number (地层编号)
material_name (岩土名称)
我们希望实现以下数据处理目标(简单说,就是对原始地层表做一次「整理+增强」):
读取地层表数据
按钻孔编号去重,保留每个钻孔的一条记录
增加一列,用于存储新的地层名称(由「地层编号 + 岩性名称」拼接而成)
步骤1:数据准备
首先,下载csv数据 并保存到你的项目目录下。
你也可以参考该csv数据准备你自己的测试数据。
步骤2:导入必要的模块
从GdiSDK的modules中导入该工作流中需要用到的模块。
CsvReader: 用于读取csv表格数据的模块
DropDuplicateRows: 用于对表格数据特定列进行数据去重的模块
AddTableColumns: 用于对表格数据增加列并对新列进行值计算的模块
PipeLine: 工作流画布,将模块添加到画布中即可组织为工作流
from gdisdk.modules import CsvReader, DropDuplicateRows, AddTableColumns
from gdisdk.pipeline import PipeLine
步骤3:数据读取
使用 CsvReader 模块读取地层表数据。
实例化模块时,需要通过 mname 参数指定模块名称,以区别相同的模块,若不指定,则默认取类名。
每个模块都有多个属性,我们可以通过设置这些属性来控制模块的行为。该案例中我们设置 file 属性为地层表的文件路径。
# ---- 实例化模块 -------
# 读取csv数据
read_csv = CsvReader(mname="ReadCsv")
read_csv.file = "地层表.csv"
若此时你想测试模块是否可以正确读取数据,可以添加以下代码并执行:
read_csv.execute()
print(read_csv.OutputTable.data.head())
这里我们可以看到,即使不添加模块至pipeline中,也可以通过模块的 execute 方法来执行模块。
步骤4:数据处理
同样的,接下来我们分别设置模块 DropDuplicateRows 和 AddTableColumns 的属性,以处理数据。
# 去除钻孔编号重复的行
drop_duplicate = DropDuplicateRows(mname="DropDuplicate")
drop_duplicate.subset = ["bore_number"] # 设置需要去重的列名,支持设置多列
# 增加一列,用于存储新的地层名称 - 地层编号+岩性名称
add_column = AddTableColumns(mname="AddColumn")
add_column.column_names = [{"name": "layer_name", "title": "岩土名称", "unit": "-"}] # 设置新列的名称、标题、单位
add_column.column_templates = {"layer_name": "{layer_number} + {material_name}"}
Note
AddTableColumns 模块支持三种方式来定义新列的值,这里我们采用的是模板:
模板: 使用Excel风格的表达式,使用
{column_name}语法静态值: 直接设置值或数组
自定义函数: 使用
function:ClassName在模板中调用自定义函数
步骤5:组织工作流
模块实例化完成后,我们就可以组织并运行工作流 (pipeline)。可以简单地把 pipeline 理解为:
若干个「模块 (module)」:每个模块只专注做好一件事,比如「读表」「去重」「加列」等
它们之间的「连线 (link)」:负责把上一个模块的输出结果,作为下一个模块的输入
每个模块除了前面提到的 属性 (attributes) 外,还有两个非常重要的概念:
输入端口 (input ports):从其他模块接收数据
输出端口 (output ports):把当前模块的计算结果输出给后续模块
在组织工作流时,我们通过 >> 符号把输出端口和输入端口连起来(表示数据流向),再用 | 把多条连接组合成一个链接组 (links)。最后用 pipeline.add_links() 把这些模块和连线添加到 pipeline 中,然后通过 pipeline.run() 一次性执行整条数据处理链路。
因此,我们可以使用 add_column.OutputTable.data.head() 方法来获取最终处理完成的表格数据。
# ----- 组织pipeline -------
# 初始化pipeline
pipeline = PipeLine(app_name="GetBoreTable", app_title="获取地层表")
# 链接模块
links = read_csv.OutputTable >> drop_duplicate.InputTable | drop_duplicate.OutputTable >> add_column.InputTable
# 添加模块和链接至pipeline
pipeline.add_links(links)
# 运行pipeline
pipeline.run()
# 获取最后一个模块 add_column 的输出表数据
print(add_column.OutputTable.data.head())
通过上述案例我们可以看到GdiSDK的核心逻辑是通过模块 (module) 和链接 (link) 来组织和执行数据处理工作流。通过增加模块和组织不同的pipeline,我们就可以快速适配不同的数据处理和应用场景,且所有这些模块和pipeline都可以被复用。
Hint
上述案例中我们没有输出最终的结果至新的csv文件中。阅读完 用户指南 (User Guide) 后,你可以尝试使用 modules.widgets.PythonCoder 模块来自定义一个输出TableData至csv文件的脚本,并把它添加到pipeline中。
案例二:写入钻孔一览表至GDIM
该案例中我们将 案例一 中的钻孔一览表数据写入到GDIM项目数据中。
我们可以基于GDIM已有的 场地工程 模板创建一个新的项目,也可以在个人后台创建一个自己的模板。这里我们选择在个人后台创建一个名为 钻孔数据存储 的模板,并基于此模板创建一个新的项目。
关于如何在GDIM中创建模板并新建项目,请查看 GDIM视频教程 。
下图为创建好的项目,数据暂为空。
步骤1:获取GDIM token
写入数据到 GDIM 前,我们必须先登录 GDIM,拿到访问权限的「令牌 (token)」,否则没有权限往项目里写入数据。
Note
Token 是根据用户名和密码生成的登录凭证,一段时间后会过期,需要重新获取。
和 GDIM 交互的大部分操作(包括读写数据)都需要提供 token。
如果你使用的是私有化部署的 GDIM,需要在
gdisdk/connectors/config/gdimConfig.yml中,把系统访问地址改成你自己的服务器地址,否则会出现用户不存在的错误。也可以通过log_in函数的host参数临时指定私有化部署的 GDIM 服务器地址。
我们导入 log_in 函数,并使用该函数获取 token。推荐通过 pipeline.update_gdim_state 一次性设置 token 与 ``proj_id``(GDIM 项目 ID),以便后续模块统一使用。
from gdisdk.connectors.gdimConnector import log_in
# 这里省略案例一中已添加的代码...
# ----- 组织pipeline ------
# 初始化pipeline
pipeline = PipeLine(app_name="GetBoreTable", app_title="获取地层表")
# --- 新增代码 ----
pipeline.update_gdim_state(
token=log_in(user_name="你的账号", password="你的密码"),
proj_id="1967572096104902658",
)
# --- 新增代码 ----
# 以下为案例一中已有的代码...
# 链接模块
links = read_csv.OutputTable >> drop_duplicate.InputTable | drop_duplicate.OutputTable >> add_column.InputTable
# ...
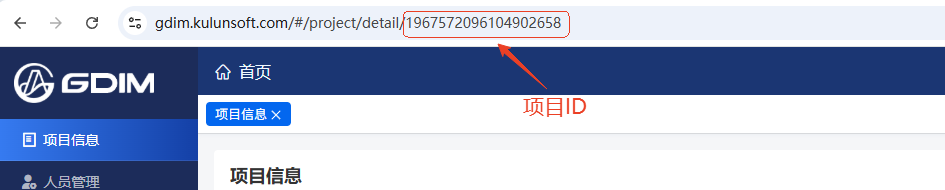
项目id是GDIM中项目的唯一标识。点击进入项目后,在 项目信息 页,你可以在地址栏如下图所示位置获取到项目ID(网页地址中从左至右的第一串数字)。需要注意的是你仅能向你具有编辑权限的表格中写入数据。
Hint
你也可以在项目根目录下创建一个 .env 文件,并添加 GDIM_USERNAME 和 GDIM_PASSWORD 变量,这样就不在需要脚本中显示的输入账号密码(仅用 log_in() 即可),以避免账号密码泄露。
GDIM_USERNAME=你的账号
GDIM_PASSWORD=你的密码
步骤2:增加写入数据至GDIM的模块
增加一个 GdimTableWriter 模块用于向GDIM数据库写入数据。设置 table_names 和 fields_mapping 属性。
table_names: 需要写入的GDIM表格的标题
fields_mapping: 当前
TableData中各字段与GDIM表格中各字段的映射关系,以确保数据写入正确的列
from gdisdk.modules.writers import GdimTableWriter # 导入 GdimTableWriter 模块
# 这里省略案例一中已添加的代码...
# 增加一列,用于存储新的地层名称 - 地层编号+岩性名称
add_column = AddTableColumns(mname="AddColumn")
add_column.column_names = [{"name": "layer_name", "title": "layer_name", "unit": "-"}] # 设置新列的名称、标题、单位
add_column.column_templates = {"layer_name": "{layer_number} + {material_name}"}
# ----- 新增模块 ------
# 写入GDIM数据模块
write_table = GdimTableWriter(mname="WriteTable")
write_table.table_names = "钻孔一览表"
write_table.fields_mapping = {
"bore_number": "钻孔编号",
"bore_top": "孔顶标高",
"layer_number": "地层编号",
"material_name": "岩性名称",
"layer_name": "地层名称",
}
# ----- 新增模块 ------
# 以下为案例一中已有的代码...
# ----- 组织pipeline -------
# 初始化pipeline
pipeline = PipeLine(app_name="GetBoreTable", app_title="获取地层表")
Tip
由于我们的样例数据中钻孔编号均为数字, pandas 读取csv文件时会自动设置钻孔编号列为整数类型,但是GDIM中钻孔编号为字符串类型,直接写入会报数据验证错误。因此我们需要设置 CsvReader 模块的 dtype 属性,将数据列 bore_number 设置为 str ,即 read_csv.dtype = {"bore_number": "str"} 。
步骤3:组织工作流
此时我们需要为新增的 GdimTableWriter 模块创建链接。
将 AddTableColumns 模块的输出端口 OutputTable 与 GdimTableWriter 模块的输入端口 InputData 进行链接。将需要写入的数据传递给 GdimTableWriter 模块。
# ---- 更新代码 ----
# 链接模块
links = (
read_csv.OutputTable >> drop_duplicate.InputTable
| drop_duplicate.OutputTable >> add_column.InputTable
| add_column.OutputTable >> write_table.InputData
)
# ---- 更新代码 ----
# 添加模块和链接至pipeline
pipeline.add_links(links)
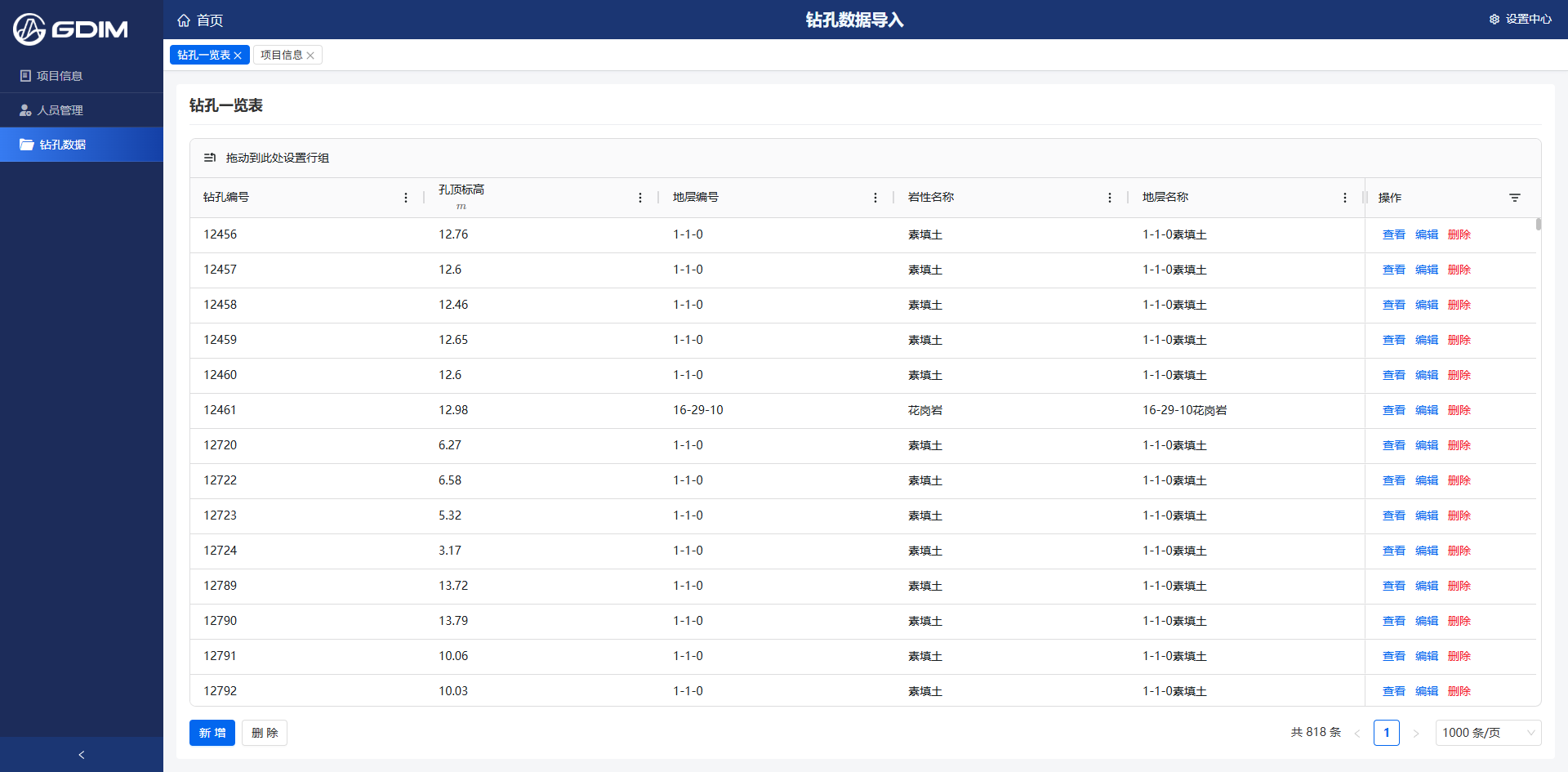
pipeline运行完成后,刷新GDIM项目中的钻孔一览表,我们即可以看到成功写入了818条数据。
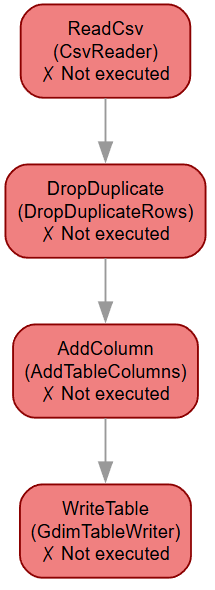
下图为该案例pipeline的工作流可视化图,你可以使用 pipeline.draw_pipeline(view=True) 方法生成该图。
Note
若需要调用 pipeline.draw_pipeline(view=True) 方法生成工作流可视化图,请确保您的开发环境满足以下要求:
本机安装 Graphviz 软件,下载地址 Graphviz官方文档 。安装时注意必须将 Graphviz 软件添加到系统环境变量中,如下图。
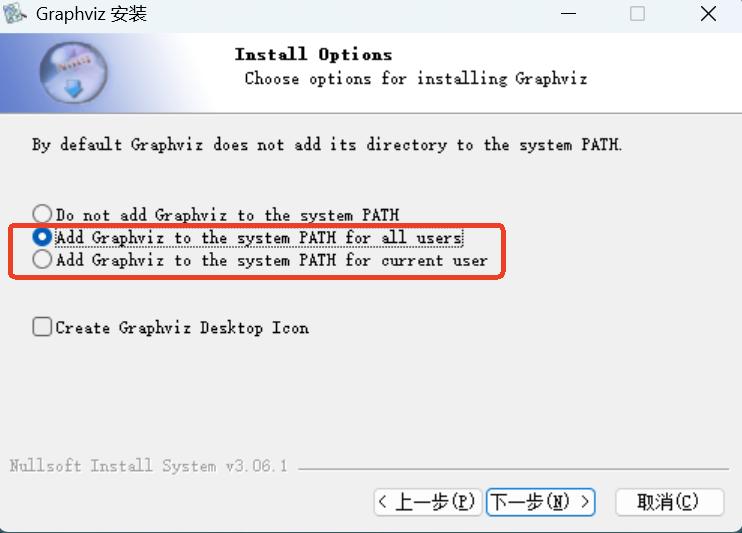
Note
该案例中 GdimTableWriter 模块的数据写入采用追加方式,即在当前表最后新增写入的数据,不会对已有数据产生影响。因此,当你反复执行此pipeline时,你会发现表中数据会越来越多。当然,我们也可以使用 GdimTableWriter 实现更复杂的数据写入机制,例如覆盖具有相同钻孔编号的数据。
步骤4:上传至GDIM数据对接应用
若我们希望该数据处理流程可以被其他用户使用,我们则需要将pipeline上传至GDIM数据对接应用中。
首先我们需要使用 pipeline.save_pipeline 方法将pipeline保存至本地。
此时,重新运行脚本,我们可以在运行目录下找到保存的 pipeline 文件 GetBoreTable.pipe。该文件中定义了我们配置的钻孔一览表数据提取工作流。
然后我们登录GDIM,进入个人后台,在项目数据模板中添加 数据对接应用,并对其进行配置即可。
关于 数据对接应用 的配置,请参考 GDIM视频教程 中关于 数据对接应用 部分的教程。
案例三:生成钻孔一览表报告
该案例中我们将基于 案例二 中写入的钻孔一览表数据生成一份 .docx 报告。
步骤1:初始化pipeline
不同于 案例一 和 案例二 ,该案例中我们先初始化 pipeline,并设置 GDIM 访问上下文(推荐使用 update_gdim_state)以及 workspace 。
from gdi.connectors.gdimConnector import log_in
from gdi.modules.readers import GdimTableReader
from gdi.modules.writers import DocDataWriter, DocPrinter
from gdi.pipeline.pipeline import PipeLine
# ----- 初始化pipeline -------
pipeline = PipeLine(app_name="GenerateDoc", app_title="生成报告")
pipeline.update_gdim_state(token=log_in(), proj_id="1967572096104902658")
pipeline.workspace = "test"
Hint
pipeline全局属性指所有pipeline中添加的模块 (module) 都可以访问的属性。
workspace属性用于指定pipeline运行时的工作目录,对于运行时需要读取和保存文件的模块,不指定具体路径时,通常默认采用pipeline工作目录。
步骤2:实例化模块
首先我们需要实例化生成报告所需的模块:
GdimTableReader: 用于读取GDIM表格数据的模块
DocDataWriter: 用于转换生成报告所需数据格式的模块
DocPrinter: 用于打印.docx报告的模块
GdimTableReader 模块中属性 table_fields 用于指定需要读取的表或表中字段。
DocDataWriter 模块中属性 precision 用于指定打印数字时需要保留的小数位数,这里我们设置所有数字均保留2位小数。
DocPrinter 模块中属性 template 用于指定报告模板文件路径,属性 output_name 用于指定打印报告的文件名。
# ---- 实例化模块 -------
# 读取GDIM表格数据
read_table = GdimTableReader(mname="ReadTable")
read_table.table_fields = ["钻孔一览表"]
# 转换生成报告所需数据格式
doc_data = DocDataWriter(mname="DocData")
doc_data.precision = 2
# 打印报告
print_doc = DocPrinter(mname="PrintDoc")
print_doc.template = "钻孔一览表模板.docx"
print_doc.output_name = "钻孔一览表.docx"
步骤3:连接模块并运行pipeline
模块属性设置完成后,即可连接模块并添加到pipeline中。但是在最终生成报告前,我们需要获取输入报告中数据的变量结构,以完成报告模板配置。因此,我们暂不连接 doc_data 和 print_doc 。运行pipeline后,我们获取 doc_data 输出端口中得到的 DocData 对象,调用其方法 export_keys_to_json 即可将变量结构输出到 bore_table_doc_keys.json 文件中。
Hint
DocData 对象即为 DocPrinter 模块打印报告所需的数据格式。
关于 DocData 的结构(data / doc_keys_struct)以及如何导出 “模板 keys / 打印数据”,可参考 DocData:报告打印的数据容器(模板 keys 与渲染数据)。
# ---- 链接模块 -------
link = read_table.OutputTables >> doc_data.InputData
# 添加模块和链接至pipeline
# 注意:即使只有一个连接,也统一使用 add_links(支持直接传入单个 Link)
pipeline.add_links(link)
# 运行pipeline
pipeline.run()
# 生成报告模板变量结构
doc_data.OutputDocData.data.export_keys_to_json("bore_table_doc_keys.json")
# (可选)导出打印数据(用于检查最终会写进报告的内容)
doc_data.OutputDocData.data.export_data_to_json("bore_table_doc_data.json")
步骤4:配置报告模板
运行上述脚本后我们可以在运行目录下得到一个名为 bore_table_doc_keys.json 的文件,该文件即为报告模板变量结构。我们可以使用记事本软件打开该文件,这里我们推荐使用 Dadroit 查看。
此时我们得到如下图所示的报告模板变量结构,这里记录了报告模板中需要用到的每一个变量的Key,即变量名称。
其中 zuan_kong_yi_lan_biao_0htodwf2 为钻孔一览表的Key, zuan_kong_bian_hao_xt0802f2 为钻孔编号列的Key, kong_ding_biao_gao_w4j1hnh6 为孔顶标高的Key, 依此类推。
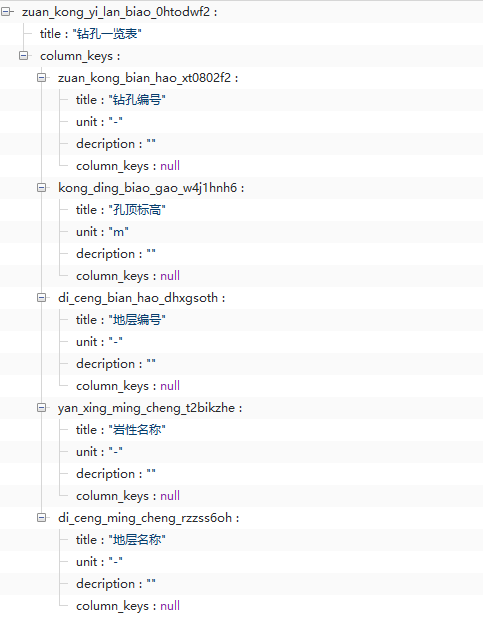
基于这些Key我们即可以配置Word模板,将变量放到 {{}} 符号中, DocPrinter 模块打印报告时即会自动根据计算得到的变量值填写报告。Word模板结构如下图所, 点击这里 可以下载该模板并根据你的变量结构编辑修改。
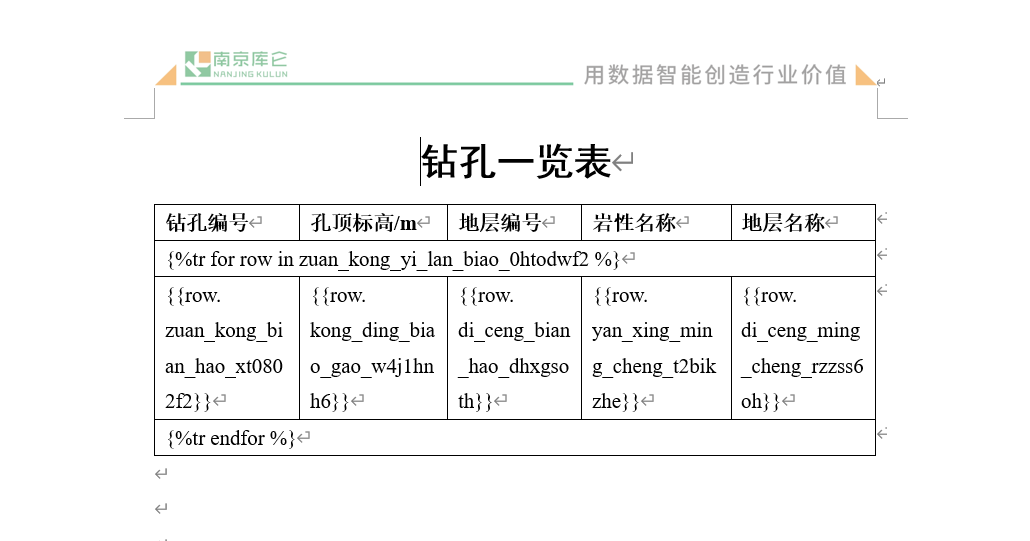
Hint
关于报告模板配置的详细教程,可以参考 GDIM视频教程 中关于 自动报告应用 部分的教程。
DocDataWriter / MergeDocData 的模块帮助与示例也可参考 modules.writers 模块帮助。
步骤5:打印报告
最后我们将 DocPrinter 模块连接到pipeline中,再次运行pipeline,即可在工作目录生成报告文件。
# ---- 链接模块 -------
links = read_table.OutputTables >> doc_data.InputData | doc_data.OutputDocData >> print_doc.InputDocData
# 添加模块和链接至pipeline
pipeline.add_links(links)
# 运行pipeline
pipeline.run()
# 生成报告模板变量结构
# doc_data.OutputDocData.data.export_keys_to_json("bore_table_doc_keys.json")
output_file = print_doc.OutputFile.data
if output_file:
print(f"报告生成成功,文件路径:{output_file}")
else:
print("报告生成失败!")
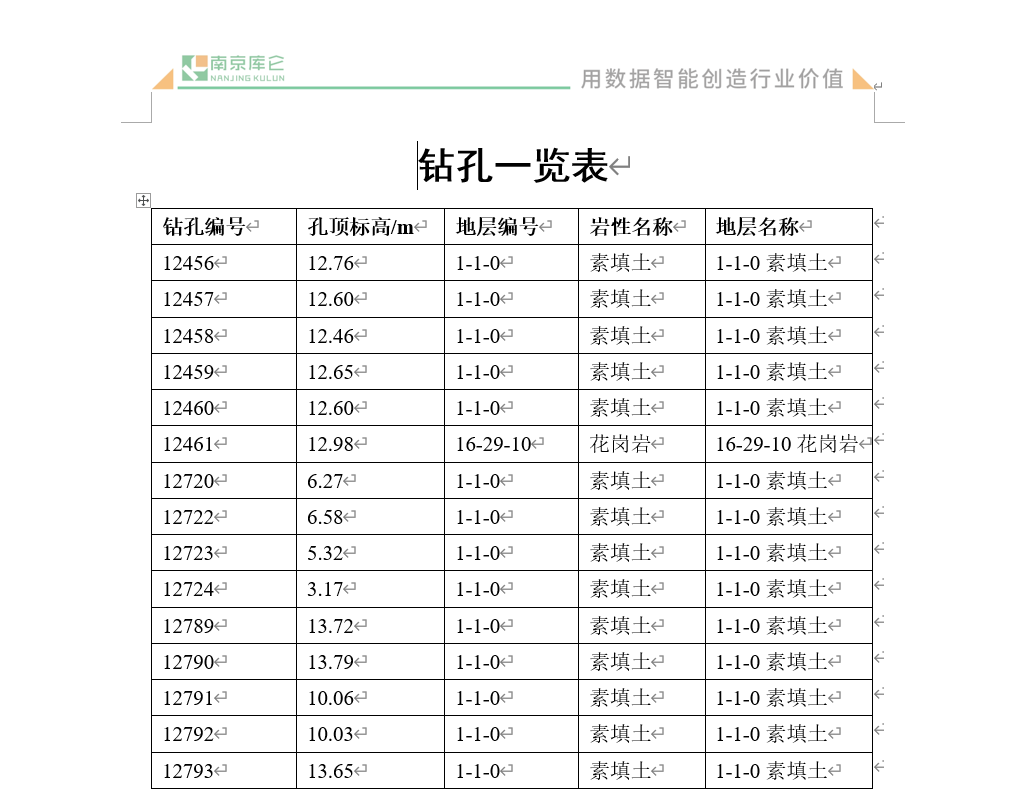
生成的报告如下图所示,可以看到其中 孔顶标高 列的数字已按照我们的设置,格式化为两位小数打印。
步骤6:添加pipeline属性并保存pipeline
如果我们希望将配置好的报告生成pipeline上传到GDIM,以供其他人使用,我们还需要为pipeline添加属性 (attributes) 并保存pipeline。
pipeline除了自带的属性,还可以将pipeline中模块 (module) 的属性添加为pipeline的属性,从而让使用pipeline的用户或程序可以直接通过pipeline属性设置pipeline中模块的属性。需要注意的是GDIM仅能通过pipeline属性为pipeline中的模块属性赋值,因此所有需要在GDIM平台上通过交互设置的模块属性,都需要添加到pipeline属性中。
保存pipeline则通过调用 save_pipeline 方法即可将pipeline中定义的工作流保存至后缀名为 .pipe 的文件中。
我们按以下步骤完成pipeline上传GDIM的最后设置:
- 添加pipeline属性:
使用
add_attribute方法添加DocPrinter模块的template属性至pipeline属性。这样GDIM即可以通过pipeline属性为模块DocPrinter设置template属性的值。该方法接受三个参数: -attr_name: 添加到pipeline中后的属性名称 -module_name: 属性所属模块名称 -param_name: 属性在模块中的原始名称 -attr_title: 添加到pipeline中后的属性标题,该值会显示到UI界面中
- 设置
DocPrinter模块的save_to_gdim属性为True: GDIM采用文件服务器,而不是直接访问服务器中的文件地址来读取生成的报告文件,因此对于本地测试,我们可以不设置该值(默认为
False)。但是当我们希望pipeline在GDIM上运行时,则需要设置该值为True,此时DocPrinter模块会将生成的报告文件上传至GDIM文件服务器,否则GDIM无法获取生成的报告文件。
- 设置
- 保存pipeline至
.pipe文件: 调用
save_pipeline方法将pipeline中定义的工作流保存至后缀名为.pipe的文件中。当仅给出文件名时,默认保存到脚本当前运行路径下,这里我们指定保存到pipeline工作目录下。
- 保存pipeline至
# 打印报告
print_doc = DocPrinter(mname="PrintDoc")
print_doc.template = "钻孔一览表模板.docx"
print_doc.output_name = "钻孔一览表.docx"
print_doc.save_to_gdim = True # 需要上传GDIM运行时设置为True,否则为False
# ---- 链接模块 -------
links = read_table.OutputTables >> doc_data.InputData | doc_data.OutputDocData >> print_doc.InputDocData
# 添加模块和链接至pipeline
pipeline.add_links(links)
# 添加pipeline属性
pipeline.add_attribute(attr_name="template", module_name="PrintDoc", param_name="template", attr_title="报告模板")
# 保存pipeline
pipeline.save_pipeline(file=f"{pipeline.workspace}/GenerateDoc.pipe")
# 运行pipeline
# 若不想运行pipeline,我们可以注释掉运行代码,仅保存pipeline
# pipeline.run()
Hint
若我们需要测试pipeline attribute 是否添加成功,可以通过pipeline的 set_attributes 方法来设置新添加的pipeline的 template 属性值。
步骤7:上传GDIM自动报告应用
pipe文件保存成功后,我们登录GDIM,进入 个人后台 ,在案例二中创建的 钻孔数据存储 模板中添加 自动报告 应用,然后我们即可上传pipe文件并配置我们的报告自动生成章节。
关于 自动报告应用 的配置,请参考 GDIM视频教程 中关于 自动报告应用 部分的教程。
下一步
现在你已经了解了GdiSDK的基本使用方法,建议你:
阅读用户指南: 深入了解pipeline底层机制和核心模块的详细功能
查看学习案例: 通过实际例子掌握GdiSDK的各种高级用法
查看模块帮助: 了解各个模块的详细功能和使用方法
探索API参考: 了解完整的类和函数接口
尝试自己的项目: 将GdiSDK应用到实际工作中
如果在使用过程中遇到问题,请查阅文档或联系技术支持。