运行调试 (Debug)
本章介绍如何在本地调试 Pipeline 运行过程,重点说明 gdisdk.pipeline.pipeline.PipeLine.run
的两个运行时参数:
verbose:在命令行窗口输出每个模块的执行过程;run_trace_file:把本次运行的结构化日志保存为JSON,并自动生成一个可直接在浏览器打开的HTML调试页面。
这两个参数适合回答下面几类常见问题:
哪个模块先执行、哪个模块后执行;
某个模块是否真的运行了;
某个模块运行慢不慢;
模块执行前拿到了什么输入、执行后产出了什么结果;
异常发生在什么模块附近。
何时使用
建议在以下场景打开调试:
新建 Pipeline 后,第一次本地联调;
修改了模块连线,想确认执行顺序是否符合预期;
某个模块没有执行,或输出为空;
某个 LLM / 读取 / 计算模块耗时异常,需要定位瓶颈;
本地脚本可以运行,但上传 GDIM 前希望先把执行链路看清楚。
Note
run_trace_file 面向 本地开发调试,不是生产日志方案。
它会在每次 run() 结束后覆盖上一次结果。
如何开启
最常见的写法如下:
from gdisdk.pipeline import PipeLine
pipeline = PipeLine(
app_name="Doc2GeologicalCondition",
workspace="pipelineImages/projects/sichuanGonglu/reportTemplates/doc2",
)
result = pipeline.run(
verbose=True,
run_trace_file="run_trace.json",
)
上面的配置表示:
verbose=True:把本次运行过程输出到命令行窗口;run_trace_file="run_trace.json":把本次运行记录保存为run_trace.json;因为这里只给了文件名,没有给目录,所以文件会保存到
pipeline.workspace下;同一次运行结束后,还会在同目录自动生成
run_trace.html,无需额外调用其他方法。
如果你只想临时看命令行,而不落盘文件,可以只写:
pipeline.run(verbose=True)
如果你已经在 PipeLine(...) 初始化时设置了 verbose 或 run_trace_file,
也可以在某一次 run() 时临时覆盖它们。
命令行看啥
打开 verbose=True 后,命令行会输出每个模块的执行开始、执行完成和耗时。
下面是真实运行日志中的一小段节选:
12:00:36.941 [9] >> SelectAttitudeTable (TableSelector)
12:00:36.942 module.execute SelectAttitudeTable
12:00:36.944 [9] ok SelectAttitudeTable 1.1 ms
...
12:00:37.886 [29] >> LLMNodeFracture (LLMNode)
12:00:37.887 module.execute LLMNodeFracture
12:00:41.142 [29] ok LLMNodeFracture 3257.6 ms
解读时可以重点看这几个信息:
[9]、[29]:本次运行中的执行序号,数字越小越早执行;SelectAttitudeTable、LLMNodeFracture:模块实例名,也就是mname;(TableSelector)、(LLMNode):模块类型;ok ... 1.1 ms:表示模块成功执行,以及该模块本次耗时;如果某个模块耗时明显更长,例如
LLMNodeFracture 3257.6 ms,就值得优先检查它是不是当前瓶颈。
适合先用命令行快速判断:
Pipeline 是否真的跑起来了;
执行顺序大体是否正确;
哪些模块特别慢;
报错大致出现在什么位置。
Trace 文件
当同时设置 verbose=True 和 run_trace_file 时,Pipeline 结束后通常会在工作目录下得到两个文件:
run_trace.json:结构化事件明细,适合精细排查;run_trace.html:浏览器可直接打开的调试页面,适合快速浏览和筛选。
以上两个文件都来自同一次运行快照。下一次运行时,如果仍写到同一路径,会覆盖上一次内容。
run_trace.json 中的记录是一个 JSON 数组,每条记录对应一个事件。下面给出某次运行的节选:
[
{
"event": "pipeline.run.start",
"pipeline_app": "Doc2GeologicalCondition",
"from_module": null,
"total_modules": 30
},
{
"event": "module.start",
"module_name": "ReadTables",
"module_class": "GdimTableReader",
"exec_seq": 0,
"input_preview": {}
},
{
"event": "module.done",
"module_name": "ReadTables",
"module_class": "GdimTableReader",
"exec_seq": 0,
"elapsed_ms": 846.7744999798015,
"output_preview": {
"OutputTable": {
"_type": "DataFrame",
"_shape": [8, 9],
"_preview": [
{
"layer_number": "1",
"material_name": "素填土"
}
]
}
}
}
]
Note
上面的 JSON 只保留了解读所需的关键字段。真实文件中还会包含 ts、level、
msg 以及更完整的输入输出预览内容。
结果解读
先看 run_trace.html 往往最直观。当前 HTML 页面通常包含以下几个区域:
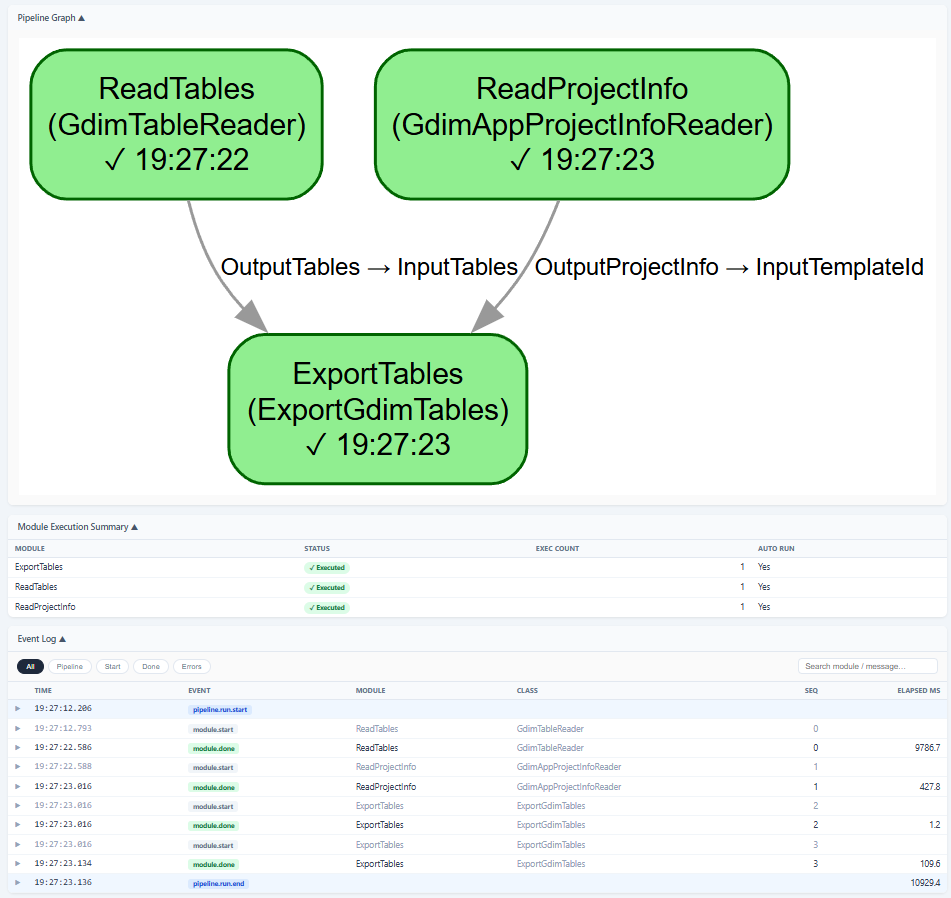
上图展示了一个 run_trace.html 的典型页面布局:上半部分是 Pipeline Graph,
中间是 Module Execution Summary,下半部分是 Event Log。实际项目中的 Pipeline
可能更复杂,但阅读方法基本一致。
Pipeline Graph
显示整个 Pipeline 的结构图;
已执行模块以绿色标识,未执行模块以红色标识;
如果某个模块没有被执行,优先检查它是否没有被上游触发、连线是否正确、
auto_run是否关闭。
Module Execution Summary
汇总每个模块是否执行、成功执行次数、
auto_run是否开启;其中
Exec Count表示该模块 成功执行的次数,不是尝试执行次数;只要模块成功执行过,图中的该模块状态就会显示为绿色;
如果某个模块的
Exec Count明显大于预期,往往说明它被重复成功执行,这通常可能是 Pipeline 变慢的原因之一;对于带循环、分支或重复触发场景的 Pipeline,
Exec Count也是判断模块执行次数是否符合预期的重要依据;适合快速确认“我以为会执行的模块,实际上到底有没有执行”。
若 Pipeline 包含
ForEachController,可通过 Notes 列区分外层模块与内层模块:🔁 ForEach · …→ 控制器本身;↳ inner [控制器名]→ 该控制器内的内层模块(在run_trace.json中对应"parent_controller"字段)。
Event Log
逐条列出本次运行中的所有事件;
可按
Pipeline、Start、Done、Errors过滤;点击某一行后,可以展开查看该条事件对应的完整 JSON 记录。
如果你更偏向直接读 run_trace.json,建议按下面顺序理解字段:
event事件类型。最常见的是:
pipeline.run.start:本次运行开始;module.start:某个模块开始执行;module.done:某个模块执行完成;module.error:某个模块执行失败;pipeline.run.end/pipeline.run.error:本次运行整体结束或失败。
exec_seq模块执行序号。适合用来恢复实际执行顺序。
elapsed_ms模块或整次运行耗时。适合定位慢模块。
input_preview模块执行前看到的输入数据预览。适合判断“上游是否真的把数据传到了这里”。
output_preview模块执行后的输出数据预览。适合判断“模块到底产出了什么”。
module_execution_summary出现在
pipeline.run.end事件中,用于汇总每个模块的执行状态、成功执行次数和auto_run状态。 对于ForEachController,控制器条目还会包含n_iterations``(最近一次触发的迭代轮数)、``n_iterations_total``(累计迭代轮数)等字段,在 HTML 报告的 Notes 列显示为 ``🔁 ForEach · …。 其内层模块条目会带有"parent_controller"与"is_inner_module": true,在 HTML 报告的 Notes 列显示为↳ inner [控制器名]。如何解读这些字段,见下文「判断循环次数是否正确」。
排查思路
下面给出几种最常见的调试思路:
1. 某个模块没有执行
先看
run_trace.html的 Module Execution Summary,确认该模块是否真的未执行;再看它的上游模块是否有
module.done;如果上游执行了但它没执行,重点检查连线是否接对,以及该模块的
auto_run是否为False。
2. 某个模块输出为空
找到这个模块对应的
module.start和module.done;对比
input_preview和output_preview;如果输入本身就是空的,问题多半在更上游;
如果输入有值但输出为空,则重点检查该模块参数和内部逻辑。
3. Pipeline 很慢
先看命令行里哪些模块耗时明显更长;
再到
run_trace.html或run_trace.json中查看对应模块的elapsed_ms;再额外检查相关模块的
Exec Count是否明显偏大,因为模块被重复成功执行也是 Pipeline 变慢的常见原因;对于 LLM、文件读取、远程接口类模块,通常最值得优先排查。
4. 运行报错
先在
Event Log中筛选Errors;找到
module.error对应的模块名;再结合前一条
module.start的input_preview,确认报错前模块到底拿到了什么输入。
5. 判断循环次数是否正确
如果你的 Pipeline 包含
ForEachController,先在 Module Execution Summary 中按 Notes 列区分模块类型:Notes 为
🔁 ForEach · …→ 控制器本身;Notes 为
↳ inner [控制器名]``(或 JSON 中带有 ``"parent_controller")→ 内层模块。
**控制器**的
Exec Count表示它在父 Pipeline 中被**触发执行的次数**(一次完整run()通常为 1),与InputIterData的迭代轮数无关;迭代轮数应查看同一行 Notes 中的 iter 信息,或 JSON 中的 ``n_iterations``(最近一次触发)/ ``n_iterations_total``(累计);**内层模块**的
Exec Count表示该模块在历次迭代中实际成功执行的次数,可与你预期的迭代次数对照; 同一列下方还会显示按控制器触发次数拆分的明细,例如:Triggers 1–5: no iterations (skipped) Trigger 6: [1, 1]
表示前 5 次触发时迭代列表为空、内层模块未运行;第 6 次触发有 2 轮迭代,方括号内从左到右依次是第 1、2 轮迭代中该模块的成功执行次数; 对应 JSON 字段为 ``foreach_exec_history``(每轮成功次数)和 ``foreach_iteration_history``(每次触发的迭代轮数);
也可在 Event Log 中搜索
controller.foreach.iter,逐轮核对iteration/total_iterations与内层模块输出;如果次数偏多,说明控制器被重复触发,或迭代绑定、触发链路存在问题;如果次数偏少,则说明某些迭代没有真正进入执行。
更多关于 ForEachController 的设计与配置,见 流程控制 (Flow Control)。
相关主题
如果你还没有写过自己的第一个 Pipeline,建议先看 新手入门 (Getting Started) 和 用户指南 (User Guide)。
如果你想继续理解 run() 的整体传播机制、auto_run、start_modules、end_modules 等底层概念,
建议再回到 运行机制 (Runtime)。
若 Pipeline 中包含 ForEachController,可参阅 流程控制 (Flow Control)。